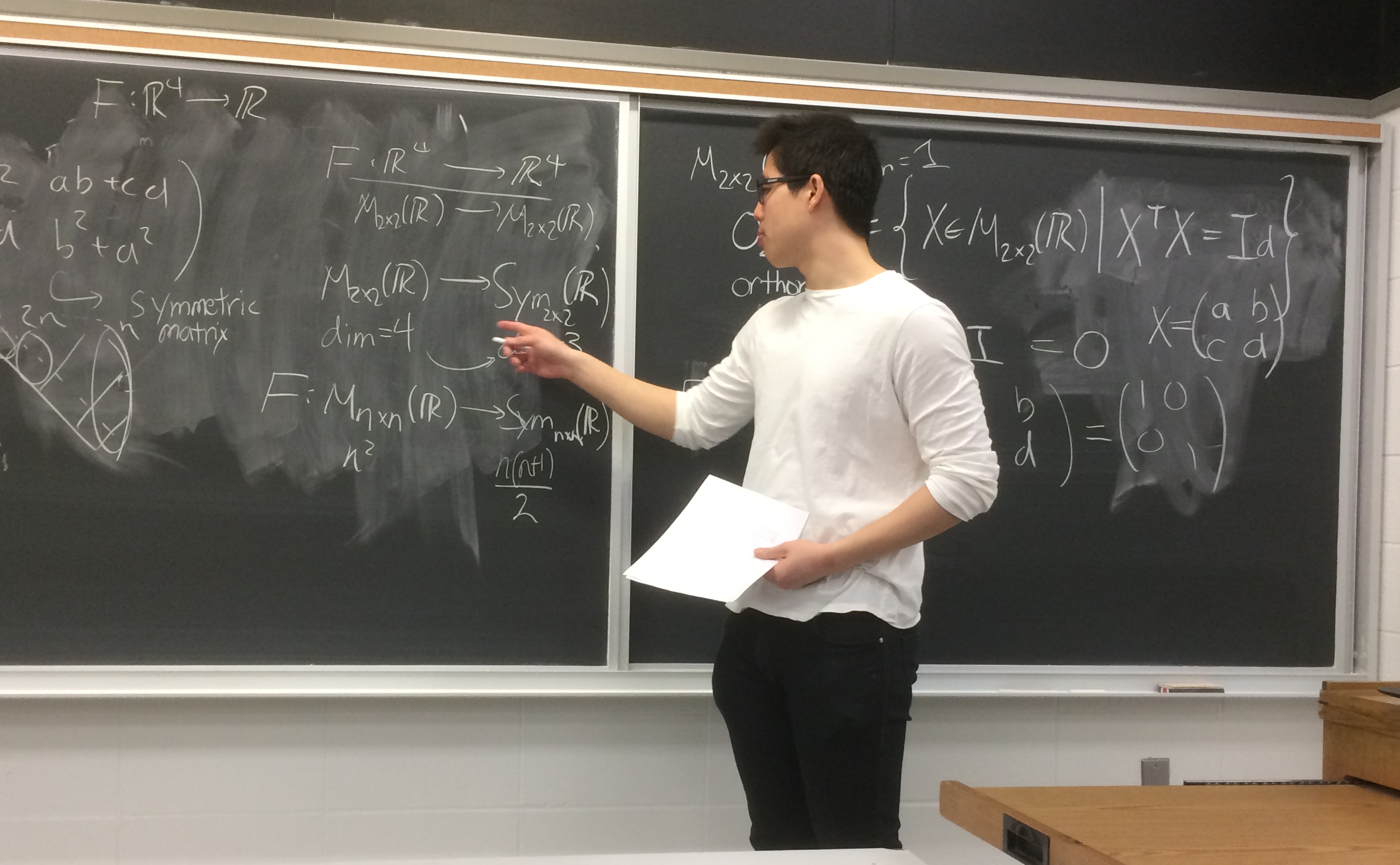Using all 8 CPUs of an AWS EC2 c4.2xlarge instance. Keep an eye on your memory!
When the University of Toronto Data Science Team participated in Data Science Bowl 2017, we had to preprocess a large dataset (~150GB, compressed) of lung CT images. I was tasked with the following:
Read data from S3 bucket
Pre-process the lung CT images, following this tutorial
Write the pre-processed image array back to S3
For S3 I/O on python, see my other post. In order to analyze the data efficiently, I used the python package multiprocessing to maximize CPU usage on an AWS compute instance. The result: Multi-CPU processing on a c4.2xlarge was 6 times faster than ordinary pre-processing on my local computer.
Working with the University of Toronto Data Science Team on kaggle competitions, there was only so much you could do on your local computer. So, when we had to analyze 100GB of satellite images for the kaggle DSTL challenge, we moved to cloud computing.
We chose AWS for its ubiquity and familiarity. To prepare the data pipeline, I downloaded the data from kaggle onto a EC2 virtual instance, unzipped it, and stored it on S3. Storing the unzipped data prevents you from having to unzip it every time you want to use the data, which takes a considerable amount of time. However, this increases the size of the data substantially and as a result, incurs higher storage costs.
Now that the data was stored on AWS, the question was: How do we programmatically access the S3 data to incorporate it into our workflow? The following details how to do so in python.
In high school, I lead an AP Physics group for one and a half years in which I taught my fellow students the AP Physics B curriculum in preparation for the AP examination. I found teaching to be a very fulfilling experience. It added a new dimension of meaning to my knowledge: I didn’t learn just for my own sake but also so I may help others learn.
In my first year at the University of Toronto, I resolved to become a Teaching Assistant. At UofT, TAs mainly teach tutorials, small interactive classes that focus on the practical applications of concepts taught in lectures. I was motivated by my own experiences in tutorials: the usefulness of having a good TA and the frustration of having a bad one. I wanted to be that good TA.
For our third-place project description, click here For the video of our presentation, click here
Last September, I participated in HackOn(Data), a two-day data hackathon in Toronto. It was the first year it was held and one of the few data science competitions in Toronto. I learned a lot, met similar-minded data enthusiasts and even ended up winning third-place with my teammate Chris!
Thus ends my 5-month flirtation with the modernist semi-auto-biography — or Künstlerroman, as the elitists say — detailing the artist’s maturation and coming to grips with Ireland and Catholicism.
“When the soul of a man is born in this country there are nets flung at it to hold it back from flight. You talk to me of nationality, language, religion. I shall try to fly by those nets”